
Along with its new Mali-G77 graphics processor and Mali-D77 display processor, Arm has unveiled its latest high-performance CPU design- the Cortex-A77. As with last year’s Cortex-A76, the Cortex-A77 is designed for premium tier applications demanding Arm’s signature low-power consumption. Everything from smartphones through to laptops and quite likely beyond.
With the Cortex-A77, Arm has targeted the maximum instructions per cycle/clock (IPC) performance increase it could manage over the Cortex-A76. Clock frequencies, power consumption, and area, are all designed to remain roughly in the same ballpark, but the new core can crunch through more instruction at once. To do this, Arm has designed an even wider core than last year and has made a number of improvements to keep the CPU core fed with things to do. But before we get to that, let’s dive into the high-level overview and performance numbers.
Hitting performance targets
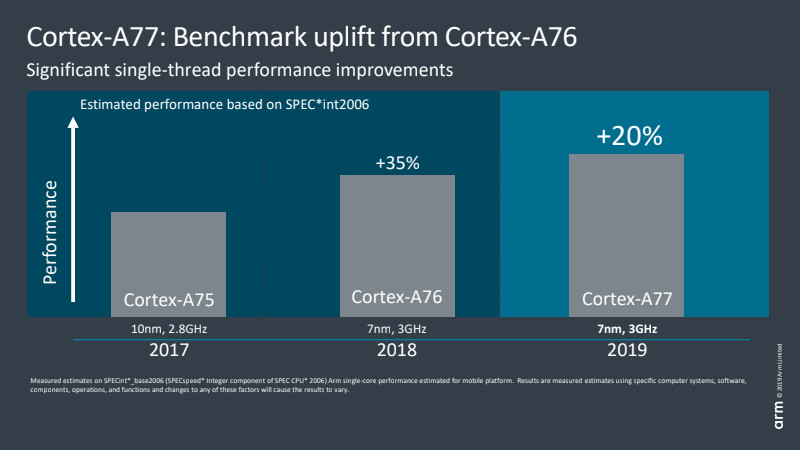
Back in August 2018, Arm uncharacteristically shared a CPU roadmap through to 2020. From 2016’s Cortex-A73 through to 2020’s “Hercules” design, the company is promising a 2.5x increase in compute performance. A fair chunk of this huge projection was accomplished with the major microarchitecture shift with the Cortex-A76, higher modern clock speeds, and the move from 16 to 10 and now 7nm manufacturing with 5nm to follow. About 1.8x of the roadmap’s gains were already achieved by last year, and the Cortex-A77 provides an approximately 20 percent further IPC boost. This puts us well on the way to Arm’s 2.5x target, although mobile devices with limited power and thermal budgets aren’t expecting to see all of these gains.
For comparison, last year’s Cortex-A76 provided around a 30-35 percent boost over the Cortex-A75. This year we’re looking at a more muted, yet still significant, 20 percent IPC gain between the A77 and A76. This is good news because it means more performance while sticking to similar thermal and power constraints as before. The trade-off is that the A77 is about 17 percent larger than the A76, so will cost a bit more in terms of silicon area. If you want a comparison with the desktop leaders, AMD managed a 15 percent IPC boost between Zen2 and Zen+, while Intel’s IPC has remained virtually static for years. Of course we’re talking different market segments here, but this demonstrates how Arm’s CPU design team has made impressive gains in recent generations.
A 20% performance boost is on offer for next-gen Cortex-A77 based SoCs
The takeaway here is that the A76 marked a major microarchitectural shift with huge performance gains, while we’re back to optimization level improvements with the A77. With that out of the way, let’s dive into what’s new in the Arm Cortex-A77.
Cortex-A77 builds on the A76 microarchitecture
The key to understanding the difference between the Cortex-A77 and A76 is to grasp what is meant by a “wider” core design. Essentially, we’re talking the ability to execute more instructions for each clock cycle, which increases the core’s throughput. There are two important parts to getting this right – increasing the number of execution units to do the processing and ensuring that these units are kept well fed with data. Let’s start with the latter part and focus in the dispatch, cache, and branch predictor parts of the SoC.
The Cortex-A77 sees a 50-percent boost to dispatch width, up to six instructions per cycle from four with the A76. That means more instructions heading to the execution core for each clock cycle for greater performance potential. The out-of-order execution window is also larger as a result, increasing to 160 entries to expose more parallelism. There’s a familiar 64K instruction-cache, while the Branch Target Buffer (BTB), which holds addresses for the branch predictor, is 33 percent larger than before to handle the growth in parallel instructions. Nothing unusual here, it’s essentially a wider version of last year’s design.

The more intriguing front-end addition is the all-new 1.5K MOP cache, which stores macro-Ops (MOPs) that are fed back in from the decode unit. Arm’s CPU architecture decodes instructions from a user’s application into smaller macro-operations and then down further into micro-ops that the execution core understands. You can see this on the diagram above in the decode section. The MOP cache is used to reduce the cost penalty of missed branches and flushes, as you keep hold of the macro-ops rather than decoding them again, and increases the core’s overall throughput. Fetches from the MOP rather than i-cache bypass the decode stage, saving one cycle. Arm states that the MOP cache can hit an 85 percent or more hit rate across a range of workloads, making it a very useful addition to the standard i-cache.
Moving down to the execution core part of the CPU, note the addition of a fourth ALU and second Branch unit. This fourth ALU boosts the processor’s general number crunching bandwidth by 50 percent. This additional ALU is capable of basic one-cycle instructions (such as ADD and SUB) plus two-cycle integer operations such a multiplication. Two of the other ALUs can only handle basic one-cycle instructions, while the final unit is charged with more advanced mathematics operations like division, multiply-accumulate, etc. The second branch unit inside the execution core doubles the number of simultaneous branch jumps the core can handle, which is useful in instances where two out of the six dispatched instructions are branch jumps. This sounds a little strange, but internal testing at Arm revealed performance benefits from adopting this second unit.
The Cortex-A77 offers improved parallelism and a new take on pre-fetch caches
Other tweaks to the CPU core include the addition of a second AES encryption pipeline. The data-store pipelines now feature dedicated issue ports to double the memory issue bandwidth. These ports were previously shared with the ALUs, which could sometimes become a bottleneck. There’s also a next-generation data perfecter to improve power efficiency while also increasing the bandwidth to system DRAM.
Part of this system in the Cortex-A77 also features an all-new “system-aware” prefetch system. This improves memory performance based on the wide range of CPU core counts, cache capacities and latencies, and memory sub-system configurations inside final devices. The dedicated hardware to talks to the Dynamic Scheduling Unit (DSU) as part of a DynamIQ CPU cluster, which monitors the usage of the shared L3 cache. The core features Dynamic distance and aggressiveness levels to reduce cache utilization in situations where L3 bandwidth is limited by other CPU cores. Higher performance cores like the Cortex-A77 are more likely to saturate DSU access to memory, while lower power cores like the A55 are unlikely to.

Fitting it all together
There are lots of small changes to the Cortex-A77 that add up to some substantial differences to its predecessor. In a nutshell, the A77s new MOP cache combined with a wider and longer instruction window helps to keep the beefed-up ALU, Branch, and memory units busy with things to do. The powerhouse Cortex-A76 design has been expanded to improve its throughput even further with the A77, without relying on higher clock speeds.
The biggest performance boosts to the Cortex-A77 arrive in the form of an integer and floating point math. This is confirmed by Arm’s internal benchmarks, which showcase a 20 to 35 percent performance boost in SPEC integer and floating point benchmarks respectively. Memory bandwidth improvements sit somewhere between 15 and 20 percent, again highlighting that the biggest gains come in the form of number crunching. Overall, these improvements give the A77 an average 20 percent uplift over the previous generation. We may also see some further, more marginal gains as a result of more advanced 7nm manufacturing processes later this year or in early 2020.
In terms of smartphones, Cortex-A77 powered SoCs are destined for high-performance, flagship products. Arm fully expects to see powerhouse design utilize 4+4 bit.LITTLE core arrangements. Given the increased throughput and slight bump to area size of the A77, we will likely see SoC designers continue down the 1+3+4 or 2+2+4 trend. With one or two powerful big cores with larger caches and higher clocks, backed up by 2 or 3 A77 cores with smaller cache sizes and lower clocks to save on power and area. Ultimately the Cortex-A77 spells good things for smartphone chips and the growing market for always-connected Arm-based laptops. Keep an eye out for silicon announcements later this year.
http://bit.ly/2d4kg1q from Android Authority http://bit.ly/2QneOII
via IFTTT
Post a Comment